
Appearance
对话式RAG
如需转载,请联系微信群主
在许多问答应用程序中,我们希望允许用户进行来回对话,这意味着应用程序需要对过去的问题和答案进行某种“记忆”,以及将这些问题和答案融入当前思维的一些逻辑。
在本指南中,我们专注于添加合并历史消息的逻辑。
我们将介绍两种方法:
- 链,我们总是在其中执行检索步骤;
- 智能体,我们在其中授予LLM关于是否以及如何执行检索步骤(或多个步骤)的自由裁量权。
Setup
依赖性
我们将在本使用指南中使用OpenAI嵌入和色度向量存储,但这里显示的所有内容都适用于任何Embeddings、VectorStore 或Retriever。
我们将使用以下软件包:
python
%%capture --no-stderr
%pip install --upgrade --quiet langchain langchain-community langchainhub langchain-chroma bs4我们需要设置环境变量OPENAI_API_KEY,这可以直接完成或从. env文件加载,如下所示:
python
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# import dotenv
# dotenv.load_dotenv()Chains (链)
让我们首先重温一下我们在RAG tutorial中LilianWeng的LLM Powered Autonomous Agents博客文章上构建的问答应用程序。
python
pip install -qU langchain-openaipython
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")python
import bs4
from langchain import hub
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 1. Load, chunk and index the contents of the blog to create a retriever.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
# 2. Incorporate the retriever into a question-answering chain.
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, prompt)
rag_chain = create_retrieval_chain(retriever, question_answer_chain)API参考:create_retrieval_chain | create_stuff_documents_chain | WebBaseLoader | ChatPromptTemplate | OpenAIEmbeddings | RecursiveCharacterTextSplitter
python
response = rag_chain.invoke({"input": "What is Task Decomposition?"})
response["answer"]python
"Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable for an agent or model. This process helps in guiding the agent through the various subgoals required to achieve the overall task efficiently. Different techniques like Chain of Thought and Tree of Thoughts can be used to decompose tasks into step-by-step processes, enhancing performance and understanding of the model's thinking process."请注意,我们使用了内置的链构造函数create_stuff_documents_chain和create_retrieval_chain,因此我们解决方案的基本成分是:
- retriever;
- prompt;
- LLM.
这将简化合并聊天记录的过程。
Adding chat history(添加聊天记录)
我们构建的链直接使用输入查询来检索相关上下文。但是在会话环境中,用户查询可能需要理解会话上下文。例如,考虑这种交换:
Human: "What is Task Decomposition?"
AI: "Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable for an agent or model."
Human: "What are common ways of doing it?"
为了回答第二个问题,我们的系统需要理解“it(它)”指的是“Task Decomposition(任务分解)”
我们需要更新有关现有应用程序的两件事:
- Prompt: 更新我们的提示以支持历史消息作为输入。
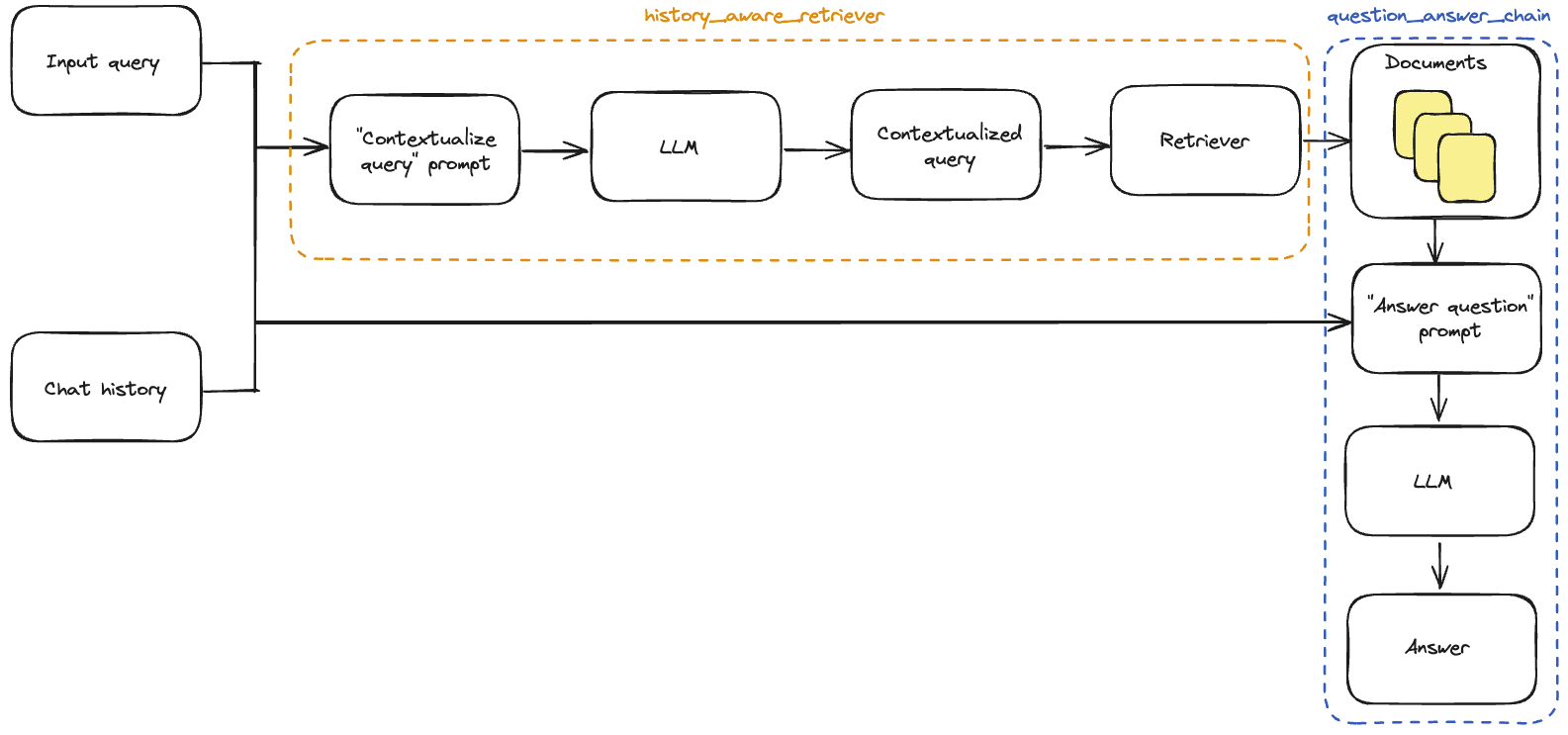
- Contextualizing questions: 添加一个子链,该子链接受最新的用户问题并在聊天历史的上下文中重新表述它。这可以简单地认为是构建一个新的“历史感知”检索器。而在我们之前:
query->retriever
现在我们将有:(query, conversation history)->LLM->rephrased query->retriever
**Contextualizing the question(**将问题置于上下文中)
首先,我们需要定义一个接受历史消息和最新用户问题的子链,如果它引用了历史信息中的任何信息,则重新制定问题。
我们将使用一个提示符,该提示符包含一个名为“chat_history”的MessagesPlacehold变量。这允许我们使用“chat_history”输入键将消息列表传递给提示符,这些消息将插入到系统消息之后和包含最新问题的人工消息之前。
请注意,我们在这一步使用了一个辅助函数create_history_aware_retriever,它管理chat_history为空的情况,否则按顺序应用prompt | llm | StrOutputParser() | retriever。create_history_aware_retriever构造一个接受键输入和chat_history作为输入的链,并具有与检索器相同的输出模式。
create_history_aware_retriever构造一个接受键输入和chat_history作为输入的链,并具有与检索器相同的输出模式。
python
from langchain.chains import create_history_aware_retriever
from langchain_core.prompts import MessagesPlaceholder
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)API Reference:create_history_aware_retriever | MessagesPlaceholder
此链将输入查询的重新措辞添加到我们的检索器,以便检索包含对话的上下文。
现在我们可以构建完整的QA链了。这就像更新检索器成为我们的新history_aware_retriever一样简单。
同样,我们将使用create_stuff_documents_chain生成一个question_answer_chain,输入键上下文、chat_history和输入——它接受检索到的上下文以及对话历史和查询来生成答案。
我们用create_retrieval_chain构建最终rag_chain。这个链按顺序应用history_aware_retriever和question_answer_chain,为了方便起见保留检索到的上下文等中间输出。它有输入键输入和chat_history,并在其输出中包括输入、chat_history、上下文和答案。
python
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)API Reference:create_retrieval_chain | create_stuff_documents_chain
让我们试试这个。下面我们提出一个问题和一个后续问题,需要上下文化以返回明智的响应。因为我们的链包括一个“chat_history”输入,所以调用者需要管理聊天记录。我们可以通过将输入和输出消息附加到列表中来实现这一点:
python
from langchain_core.messages import AIMessage, HumanMessage
chat_history = []
question = "What is Task Decomposition?"
ai_msg_1 = rag_chain.invoke({"input": question, "chat_history": chat_history})
chat_history.extend(
[
HumanMessage(content=question),
AIMessage(content=ai_msg_1["answer"]),
]
)
second_question = "What are common ways of doing it?"
ai_msg_2 = rag_chain.invoke({"input": second_question, "chat_history": chat_history})
print(ai_msg_2["answer"])API Reference:AIMessage | HumanMessage
python
Task decomposition can be achieved through various methods such as using techniques like Chain of Thought (CoT) or Tree of Thoughts to break down complex tasks into smaller steps. Common ways include prompting the model with simple instructions like "Steps for XYZ" or task-specific instructions like "Write a story outline." Human inputs can also be used to guide the task decomposition process effectively.聊天历史的状态管理#
在这里,我们已经讨论了如何添加应用程序逻辑来合并历史输出,但是我们仍然手动更新聊天历史并将其插入到每个输入中。在一个真正的问答应用程序中,我们需要一些持久化聊天历史的方法和一些自动插入和更新它的方法。
为此,我们可以使用:
- BaseChatMessageHistory: 存储聊天记录。
- RunnableWithMessageHistory: LCEL链和BaseChatMessageHistory的包装器,处理将聊天历史注入输入并在每次调用后更新它。
有关如何一起使用这些类来创建有状态会话链的详细指南,请访问How to add message history (memory) LCEL页面。
下面,我们实现第二个选项的一个简单示例,其中聊天历史存储在一个简单的命令中。LangChain管理与Redis和其他技术的内存集成,以提供更强大的持久性。
RunnableWithMessageHistory实例为您管理聊天记录。它们接受一个带有一个键(默认为“session_id”)的配置,该键指定要获取和添加到输入的对话历史记录,并将输出附加到相同的对话历史记录。下面是一个例子:
python
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)API Reference:ChatMessageHistory | BaseChatMessageHistory | RunnableWithMessageHistory
python
conversational_rag_chain.invoke(
{"input": "What is Task Decomposition?"},
config={
"configurable": {"session_id": "abc123"}
}, # constructs a key "abc123" in `store`.
)["answer"]python
'Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable. Techniques like Chain of Thought (CoT) and Tree of Thoughts help models decompose hard tasks into multiple manageable subtasks. This process allows agents to plan ahead and tackle intricate tasks effectively.'python
conversational_rag_chain.invoke(
{"input": "What are common ways of doing it?"},
config={"configurable": {"session_id": "abc123"}},
)["answer"]python
'Task decomposition can be achieved through various methods such as using Language Model (LLM) with simple prompting, task-specific instructions tailored to the specific task at hand, or incorporating human inputs to break down the task into smaller components. These approaches help in guiding agents to think step by step and decompose complex tasks into more manageable subgoals.'可以在存储中查看对话历史记录:
python
for message in store["abc123"].messages:
if isinstance(message, AIMessage):
prefix = "AI"
else:
prefix = "User"
print(f"{prefix}: {message.content}\n")python
User: What is Task Decomposition?
AI: Task decomposition involves breaking down complex tasks into smaller and simpler steps to make them more manageable. Techniques like Chain of Thought (CoT) and Tree of Thoughts help models decompose hard tasks into multiple manageable subtasks. This process allows agents to plan ahead and tackle intricate tasks effectively.
User: What are common ways of doing it?
AI: Task decomposition can be achieved through various methods such as using Language Model (LLM) with simple prompting, task-specific instructions tailored to the specific task at hand, or incorporating human inputs to break down the task into smaller components. These approaches help in guiding agents to think step by step and decompose complex tasks into more manageable subgoals.把它绑在一起
为方便起见,我们将所有必要的步骤结合在一个代码单元中:
python
import bs4
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_chroma import Chroma
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
### Construct retriever ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
### Contextualize question ###
contextualize_q_system_prompt = (
"Given a chat history and the latest user question "
"which might reference context in the chat history, "
"formulate a standalone question which can be understood "
"without the chat history. Do NOT answer the question, "
"just reformulate it if needed and otherwise return it as is."
)
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
### Answer question ###
system_prompt = (
"You are an assistant for question-answering tasks. "
"Use the following pieces of retrieved context to answer "
"the question. If you don't know the answer, say that you "
"don't know. Use three sentences maximum and keep the "
"answer concise."
"\n\n"
"{context}"
)
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
### Statefully manage chat history ###
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
conversational_rag_chain = RunnableWithMessageHistory(
rag_chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
output_messages_key="answer",
)API Reference:create_history_aware_retriever | create_retrieval_chain | create_stuff_documents_chain | ChatMessageHistory | WebBaseLoader | BaseChatMessageHistory | ChatPromptTemplate | MessagesPlaceholder | RunnableWithMessageHistory | ChatOpenAI | OpenAIEmbeddings | RecursiveCharacterTextSplitter
python
conversational_rag_chain.invoke(
{"input": "What is Task Decomposition?"},
config={
"configurable": {"session_id": "abc123"}
}, # constructs a key "abc123" in `store`.
)["answer"]python
'Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It involves transforming big tasks into multiple manageable tasks to facilitate problem-solving. Different methods like Chain of Thought and Tree of Thoughts can be employed to decompose tasks effectively.'python
conversational_rag_chain.invoke(
{"input": "What are common ways of doing it?"},
config={"configurable": {"session_id": "abc123"}},
)["answer"]python
'Task decomposition can be achieved through various methods such as using prompting techniques like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", providing task-specific instructions like "Write a story outline," or incorporating human inputs to break down complex tasks into smaller components. These approaches help in organizing thoughts and planning ahead for successful task completion.'Agents (智能体)
智能体利用LLM的推理能力在执行过程中做出决策。智能体允许您在检索过程中卸载一些自由裁量权。尽管它们的行为不如链可预测,但它们在这种情况下提供了一些优势:智能体直接生成检索器的输入,而不一定需要我们像上面那样在上下文化中显式构建;智能体可以执行多个检索步骤来服务于查询,或者完全不执行检索步骤(例如,响应用户的通用问候)。
Retrieval tool (检索工具)
智能体可以访问“工具”并管理它们的执行。在这种情况下,我们将把我们的检索器转换为可供智能体使用的LangChain工具:
python
from langchain.tools.retriever import create_retriever_tool
tool = create_retriever_tool(
retriever,
"blog_post_retriever",
"Searches and returns excerpts from the Autonomous Agents blog post.",
)
tools = [tool]API Reference:create_retriever_tool
工具是LangChain Runnables,实现常用接口:
python
tool.invoke("task decomposition")python
Error in LangChainTracer.on_tool_end callback: TracerException("Found chain run at ID 0ec120e2-b1fc-4593-9fee-2dd4f4cae256, but expected {'tool'} run.")python
'Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.'Agent constructor (智能体构造函数)
现在我们已经定义了工具和LLM,我们可以创建智能体了。我们将使用LangGraph来构造智能体。目前我们使用一个高级接口来构造智能体,但是LangGraph的好处是这个高级接口由一个低级的、高度可控的API支持,以防您想修改智能体逻辑。
python
from langgraph.prebuilt import create_react_agent
agent_executor = create_react_agent(llm, tools)我们现在可以试一试了。请注意,到目前为止它还不是有状态的(我们仍然需要在内存中添加)
python
query = "What is Task Decomposition?"
for s in agent_executor.stream(
{"messages": [HumanMessage(content=query)]},
):
print(s)
print("----")python
Error in LangChainTracer.on_tool_end callback: TracerException("Found chain run at ID 1a50f4da-34a7-44af-8cbb-c67c90c9619e, but expected {'tool'} run.")
``````output
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_1ZkTWsLYIlKZ1uMyIQGUuyJx', 'function': {'arguments': '{"query":"Task Decomposition"}', 'name': 'blog_post_retriever'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 68, 'total_tokens': 87}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-dddbe2d2-2355-4ca5-9961-1ceb39d78cf9-0', tool_calls=[{'name': 'blog_post_retriever', 'args': {'query': 'Task Decomposition'}, 'id': 'call_1ZkTWsLYIlKZ1uMyIQGUuyJx'}])]}}
----
{'tools': {'messages': [ToolMessage(content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', name='blog_post_retriever', tool_call_id='call_1ZkTWsLYIlKZ1uMyIQGUuyJx')]}}
----
{'agent': {'messages': [AIMessage(content='Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. This approach helps in managing and solving difficult tasks by dividing them into more manageable components. One common method of task decomposition is the Chain of Thought (CoT) technique, where models are instructed to think step by step to decompose hard tasks into smaller steps. Another extension of CoT is the Tree of Thoughts, which explores multiple reasoning possibilities at each step and generates multiple thoughts per step, creating a tree structure. Task decomposition can be facilitated by using simple prompts, task-specific instructions, or human inputs.', response_metadata={'token_usage': {'completion_tokens': 119, 'prompt_tokens': 636, 'total_tokens': 755}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-4a701854-97f2-4ec2-b6e1-73410911fa72-0')]}}
----LangGraph内置了持久性,因此我们不需要使用ChatMessage历史!相反,我们可以直接将检查指针传递给我们的LangGraph智能体
python
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:")
agent_executor = create_react_agent(llm, tools, checkpointer=memory)这就是我们构建对话式RAG智能体所需的全部内容。让我们观察它的行为。请注意,如果我们输入不需要检索步骤的查询,智能体不会执行:
python
config = {"configurable": {"thread_id": "abc123"}}
for s in agent_executor.stream(
{"messages": [HumanMessage(content="Hi! I'm bob")]}, config=config
):
print(s)
print("----")python
{'agent': {'messages': [AIMessage(content='Hello Bob! How can I assist you today?', response_metadata={'token_usage': {'completion_tokens': 11, 'prompt_tokens': 67, 'total_tokens': 78}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-022806f0-eb26-4c87-9132-ed2fcc6c21ea-0')]}}
----此外,如果我们输入确实需要检索步骤的查询,智能体会生成对工具的输入:
python
query = "What is Task Decomposition?"
for s in agent_executor.stream(
{"messages": [HumanMessage(content=query)]}, config=config
):
print(s)
print("----")python
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_DdAAJJgGIQOZQgKVE4duDyML', 'function': {'arguments': '{"query":"Task Decomposition"}', 'name': 'blog_post_retriever'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 91, 'total_tokens': 110}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-acc3c903-4f6f-48dd-8b36-f6f3b80d0856-0', tool_calls=[{'name': 'blog_post_retriever', 'args': {'query': 'Task Decomposition'}, 'id': 'call_DdAAJJgGIQOZQgKVE4duDyML'}])]}}
----
``````output
Error in LangChainTracer.on_tool_end callback: TracerException("Found chain run at ID 9a7ba580-ec91-412d-9649-1b5cbf5ae7bc, but expected {'tool'} run.")
``````output
{'tools': {'messages': [ToolMessage(content='Fig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nTree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', name='blog_post_retriever', tool_call_id='call_DdAAJJgGIQOZQgKVE4duDyML')]}}
----上面,智能体没有将我们的查询逐字插入工具中,而是删除了“什么”和“是”等不必要的单词。同样的原则允许代理在必要时使用对话的上下文:
python
query = "What according to the blog post are common ways of doing it? redo the search"
for s in agent_executor.stream(
{"messages": [HumanMessage(content=query)]}, config=config
):
print(s)
print("----")python
{'agent': {'messages': [AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_KvoiamnLfGEzMeEMlV3u0TJ7', 'function': {'arguments': '{"query":"common ways of task decomposition"}', 'name': 'blog_post_retriever'}, 'type': 'function'}]}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 930, 'total_tokens': 951}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-dd842071-6dbd-4b68-8657-892eaca58638-0', tool_calls=[{'name': 'blog_post_retriever', 'args': {'query': 'common ways of task decomposition'}, 'id': 'call_KvoiamnLfGEzMeEMlV3u0TJ7'}])]}}
----
{'action': {'messages': [ToolMessage(content='Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS (breadth-first search) or DFS (depth-first search) with each state evaluated by a classifier (via a prompt) or majority vote.\nTask decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\n\nFig. 1. Overview of a LLM-powered autonomous agent system.\nComponent One: Planning#\nA complicated task usually involves many steps. An agent needs to know what they are and plan ahead.\nTask Decomposition#\nChain of thought (CoT; Wei et al. 2022) has become a standard prompting technique for enhancing model performance on complex tasks. The model is instructed to “think step by step” to utilize more test-time computation to decompose hard tasks into smaller and simpler steps. CoT transforms big tasks into multiple manageable tasks and shed lights into an interpretation of the model’s thinking process.\n\nResources:\n1. Internet access for searches and information gathering.\n2. Long Term memory management.\n3. GPT-3.5 powered Agents for delegation of simple tasks.\n4. File output.\n\nPerformance Evaluation:\n1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.\n2. Constructively self-criticize your big-picture behavior constantly.\n3. Reflect on past decisions and strategies to refine your approach.\n4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.\n\n(3) Task execution: Expert models execute on the specific tasks and log results.\nInstruction:\n\nWith the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user\'s request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.', name='blog_post_retriever', id='c749bb8e-c8e0-4fa3-bc11-3e2e0651880b', tool_call_id='call_KvoiamnLfGEzMeEMlV3u0TJ7')]}}
----
{'agent': {'messages': [AIMessage(content='According to the blog post, common ways of task decomposition include:\n\n1. Using language models with simple prompting like "Steps for XYZ" or "What are the subgoals for achieving XYZ?"\n2. Utilizing task-specific instructions, for example, using "Write a story outline" for writing a novel.\n3. Involving human inputs in the task decomposition process.\n\nThese methods help in breaking down complex tasks into smaller and more manageable steps, facilitating better planning and execution of the overall task.', response_metadata={'token_usage': {'completion_tokens': 100, 'prompt_tokens': 1475, 'total_tokens': 1575}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': 'fp_3b956da36b', 'finish_reason': 'stop', 'logprobs': None}, id='run-98b765b3-f1a6-4c9a-ad0f-2db7950b900f-0')]}}
----请注意,智能体能够推断出我们查询中的“it”指的是“任务分解”,并生成了一个合理的搜索查询作为结果——在本例中是“任务分解的常见方式”。
Tying it together
为方便起见,我们将所有必要的步骤结合在一个代码单元中:
python
import bs4
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain.tools.retriever import create_retriever_tool
from langchain_chroma import Chroma
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.checkpoint.sqlite import SqliteSaver
memory = SqliteSaver.from_conn_string(":memory:")
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
### Construct retriever ###
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
### Build retriever tool ###
tool = create_retriever_tool(
retriever,
"blog_post_retriever",
"Searches and returns excerpts from the Autonomous Agents blog post.",
)
tools = [tool]
agent_executor = create_react_agent(llm, tools, checkpointer=memory)API Reference:AgentExecutor | create_tool_calling_agent | create_retriever_tool | ChatMessageHistory | WebBaseLoader | BaseChatMessageHistory | ChatPromptTemplate | MessagesPlaceholder | RunnableWithMessageHistory | ChatOpenAI | OpenAIEmbeddings | RecursiveCharacterTextSplitter\
后续步骤
我们已经介绍了构建基本会话问答应用程序的步骤:
- 我们使用链来构建一个可预测的应用程序,为每个用户输入生成搜索查询;
- 我们使用智能体构建了一个“决定”何时以及如何生成搜索查询的应用程序。
要探索不同类型的检索器和检索策略,请访问操作指南的检索器 retrievers 部分。
要详细走查LangChain的对话记忆抽象,请访问How to add message history (memory) LCEL页面。
要了解有关智能体的更多信息,请访问 Agents Modules.
如需转载,请联系微信群主
加群:
扫描下方二维码加好友,添加申请填写“ai加群”,成功添加后,回复“ai加群”或耐心等待管理员邀请你入群